
Tips para optimización de queries en SQL Server (1)
Más que conocer trucos y sintaxis, escribir un buen query (consulta) en SQL Server exige un ejercicio constante en ser capaz de crear queries relacionales “elegantes”. Por lo general estos últimos dan mucho mejores resultados –claro, siempre que la base esté también correctamente relacionada, lo que podríamos ver luego-.
Pues aquí trataremos dos tips indispensables al momento de escribir consultas o queries en SQL Server. Dejaremos otros tips para el futuro, o si tienen alguno, coméntenlo sin problemas.
Consultar únicamente las filas y columnas requeridas
Puede sonar bastante obvio, pero a la vez es una estrategia bastante buena al momento de elaborar queries. Es muy común que alguna consulta devuelva o muchas columnas o muchas filas. Si estamos retornando muchas columnas, seguramente nuestro query está abusando del “SELECT * FROM …”. Pues noticia: estas columnas de la sentencia SELECT también son tomadas en cuenta por el motor de la base de datos (concretamente el optimizador), cuando evalua el índice a utilizar en la consulta y armar el plan de ejecución de la misma. A parte de retornar muchas veces datos irrelevantes, también puede forzar barridos de índices (index scan), en lugar de las restricciones que puedan surgir debido a la cláusula WHERE. Esto debido a que el costo de ir al índice agrupado (clustered index) para devolver el resto de datos de la fila después de utilizar un índice no agrupado (nonclustered index) para limitar los resultados, puede resultar más elevado que “barrer” el índice agrupado.
A continuación un ejemplo.
select * from northwind.dbo.Orders where OrderDate < '01/01/1996'
select Orderid from northwind.dbo.Orders where OrderDate < '01/01/1996'
Estos dos queries tienen los siguientes planes de ejecución:
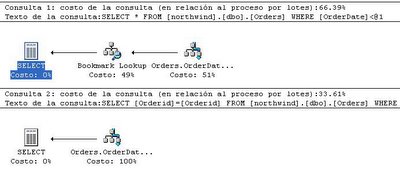
En el primer caso, a pesar de existir un índice en la tabla por el campo OrderDate, notamos que hace un “barrido” del índice agrupado, para poder mostrarlos demás datos. En el segundo caso, como únicamente tiene que mostrar el campo OrderId, y dado que OrderId forma parte del índice agrupado, únicamente realiza una búsqueda sobre el índice OrderDate. Los números hablan por sí solos.
Evitar operadores costosos, como el NOT LIKE.
Algunos operadores, tanto en los joins como en los predicados del WHERE, tienden a producir operaciones muy costosas. El operador LIKE con un valor encerrado entre los comodines (“%valor%”) casi siempre producen un barrido de la tabla (ni siquiera del índice). Si lo utilizamos con únicamente un lado del comodín, podrá hacer uso del índice, dado que el índice es parte de un árbol B+ (para aquellos que pensaban que estructura de datos en la U no iba a servir, ¡toma!), y el índice es consultado haciendo comparaciones de izquierda a derecha.
Por Dios, ni se les ocurra utilizar operadores negativos (<>, NOT LIKE) dado que casi nunca el optimizador los resuelve eficientemente. Escriban las consultas de cualquier otra manera. Si por último, están tratando de verificar existencia, utilicen mejor el IF EXISTS o IF NOT EXISTS. Si ya están en la obligación de hacer un barrido, se puede detener el barrido en la primera ocurrencia.
Recuerden siempre primero medir sus resultados actuales y luego comparar contra el optimizado. Créanme que es un mundo de diferencia.
Pues aquí trataremos dos tips indispensables al momento de escribir consultas o queries en SQL Server. Dejaremos otros tips para el futuro, o si tienen alguno, coméntenlo sin problemas.
Consultar únicamente las filas y columnas requeridas
Puede sonar bastante obvio, pero a la vez es una estrategia bastante buena al momento de elaborar queries. Es muy común que alguna consulta devuelva o muchas columnas o muchas filas. Si estamos retornando muchas columnas, seguramente nuestro query está abusando del “SELECT * FROM …”. Pues noticia: estas columnas de la sentencia SELECT también son tomadas en cuenta por el motor de la base de datos (concretamente el optimizador), cuando evalua el índice a utilizar en la consulta y armar el plan de ejecución de la misma. A parte de retornar muchas veces datos irrelevantes, también puede forzar barridos de índices (index scan), en lugar de las restricciones que puedan surgir debido a la cláusula WHERE. Esto debido a que el costo de ir al índice agrupado (clustered index) para devolver el resto de datos de la fila después de utilizar un índice no agrupado (nonclustered index) para limitar los resultados, puede resultar más elevado que “barrer” el índice agrupado.
A continuación un ejemplo.
select * from northwind.dbo.Orders where OrderDate < '01/01/1996'
select Orderid from northwind.dbo.Orders where OrderDate < '01/01/1996'
Estos dos queries tienen los siguientes planes de ejecución:

En el primer caso, a pesar de existir un índice en la tabla por el campo OrderDate, notamos que hace un “barrido” del índice agrupado, para poder mostrarlos demás datos. En el segundo caso, como únicamente tiene que mostrar el campo OrderId, y dado que OrderId forma parte del índice agrupado, únicamente realiza una búsqueda sobre el índice OrderDate. Los números hablan por sí solos.
Evitar operadores costosos, como el NOT LIKE.
Algunos operadores, tanto en los joins como en los predicados del WHERE, tienden a producir operaciones muy costosas. El operador LIKE con un valor encerrado entre los comodines (“%valor%”) casi siempre producen un barrido de la tabla (ni siquiera del índice). Si lo utilizamos con únicamente un lado del comodín, podrá hacer uso del índice, dado que el índice es parte de un árbol B+ (para aquellos que pensaban que estructura de datos en la U no iba a servir, ¡toma!), y el índice es consultado haciendo comparaciones de izquierda a derecha.
Por Dios, ni se les ocurra utilizar operadores negativos (<>, NOT LIKE) dado que casi nunca el optimizador los resuelve eficientemente. Escriban las consultas de cualquier otra manera. Si por último, están tratando de verificar existencia, utilicen mejor el IF EXISTS o IF NOT EXISTS. Si ya están en la obligación de hacer un barrido, se puede detener el barrido en la primera ocurrencia.
Recuerden siempre primero medir sus resultados actuales y luego comparar contra el optimizado. Créanme que es un mundo de diferencia.
